Problem Set #2 - Deep Learning and Time Series Analysis
Submit your coding problems in separate folders. If you use notebooks, provide a brief explanation for each question using the markdown functionality. I encourage you to discuss the problems, but when you write down the solution please do it on your own. You can raise and answer each other’s questions on Moodle; but please don’t provide exact solutions. Submit Jupyter notebooks (or scripts) for all problems.
Problem 0: Learning by Recall and Application
One of the best ways to solidify your understanding of a new topic is to actively recall what you’ve learned and apply it to a problem of your own choosing. The following steps are a guide to help you do just that.
-
Grab a paper and pen (or type in a plain text editor without searching) and try to recall everything we’ve covered so far. Start by asking yourself: how do I fit a function? What’s a linear model? What is linear regression? What was the role of the square loss? What if I use an absolute loss? How was it related to likelihood function? Write down everything you remember; definitions, key concepts, equations, and intuitions. If you get stuck, move on and return to it later. I recommend you do this for at least 2 hours.
-
Define a Problem of Interest: Think of a real dataset you’d be curious to explore. Describe the data: Is it a time series? Images? Text? Something else? What are the variables you’re working with? What do the observations look like? What structure does the dataset have?
-
Formulate Hypotheses and Models: Based on your problem, define the models you’d consider using. Will it be linear regression, logistic regression, neural networks, or something else? Write down a few equations describing how the model works. Consider the number of parameters in your model and what they represent.
-
Define the Purpose of Your Model: What will you do with your trained model? Who is it for? What insights or predictions does it provide? What are the potential challenges or limitations? How do you know that it’s working?
-
Identify Knowledge Gaps: As you go through this process, write down any questions or gaps in your understanding. What concepts or techniques do you feel unsure about? Are there methods beyond what we’ve covered that might help?
-
Refine and Expand: Once you have your initial notes, check them against your class notes. What did you miss? Now, leverage AI: Drop your notes into ChatGPT and ask it to edit for clarity, suggest questions to test your understanding, and help with coding implementation and additional ideas.
-
Write Your Report: Find a dataset online related to your problem, and review your process. What adjustments do you have to make to your approach? Your final submission should be structured as an article that includes the problem definition, dataset description, hypotheses and models, mathematical formulation, coding steps, and insights gained. Write it all down in a Jupyter notebook. Applying your approach to the dataset gets extra credit, but is not required for this problem. If you’re using ChatGPT, make sure to include the prompts you used, and attach your conversation with it as a PDF.
Problem 1: Neural Networks (30 points)
Let \(X = \{ x^{(1)}, \ldots, x^{(m)} \}\) be a dataset of \(m\) samples with 2 features, i.e. \(x^{(i)} \in \mathbb R^2\). The samples are classified into 2 categories with labels \(y^{(i)} \in \{0, 1\}\). A scatter plot of the dataset is shown in Figure 1:

The examples in class 1 are marked as \(\times\) and examples in class 0 are marked as \(\circ\). We want to perform a binary classification using a neural network with the architecture shown in Figure 2
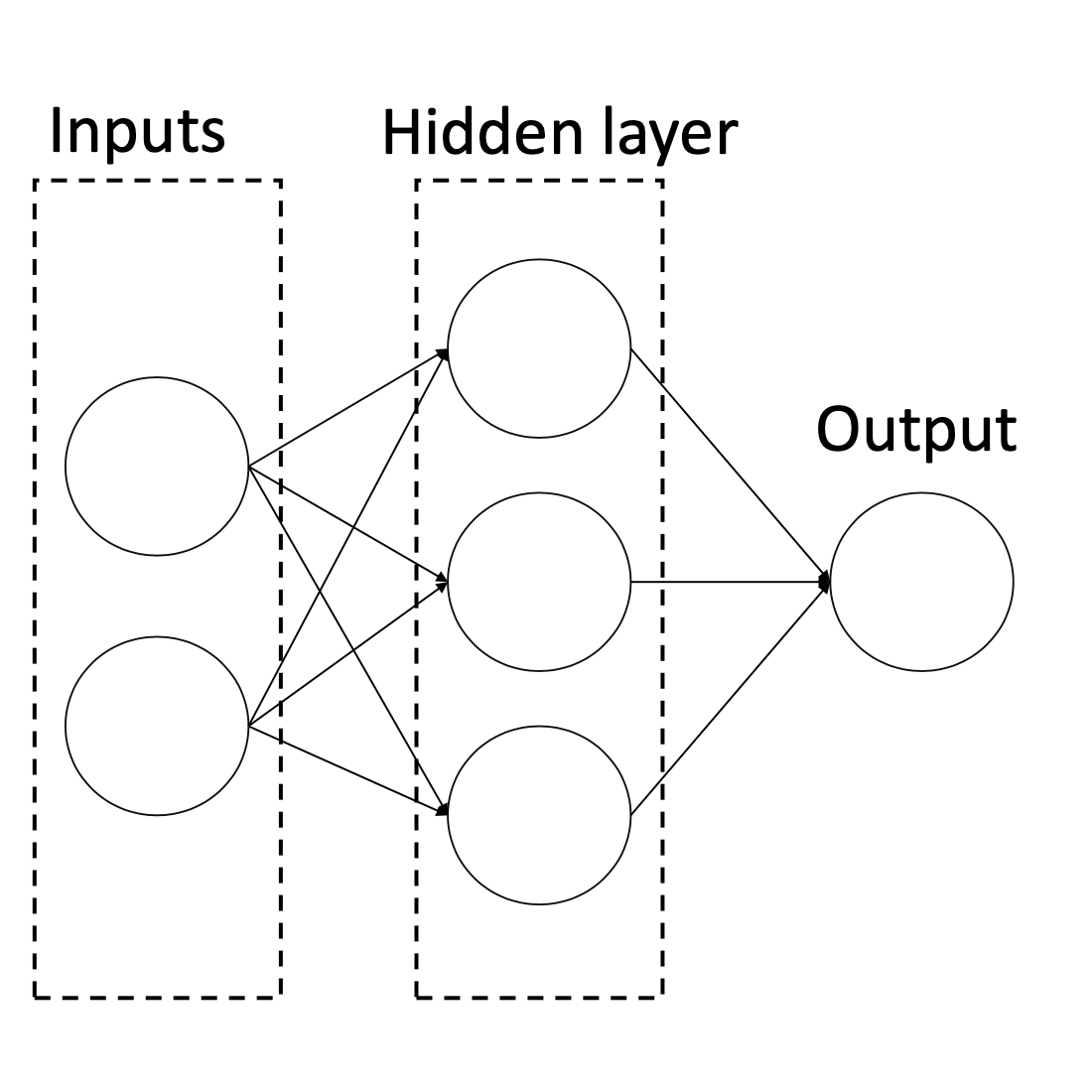
Denote the two features \(x_1\) and \(x_2\), the three neurons in the hidden layer \(a_1\), \(a_2\), and \(a_3\), and the output neuron as \(\hat y\). Let the weight from \(x_i\) to \(a_j\) be \(w_{ij}^{(1)}\) for \(i \in \{1, 2\}\), \(j \in \{1, 2, 3\}\), and the weight from \(a_j\) to \(\hat y\) be \(w_j^{(2)}\). Finally, denote the intercept weight (i.e. bias) for \(a_j\) as \(w_{0j}^{(1)}\), and the intercept weight for \(\hat y\) as \(w_0^{(2)}\). For the loss function, we’ll use average squared loss:
\[\begin{equation} L(y, \hat y) = \frac{1}{m} \sum_{i=1}^{m} \left( \hat y^{(i)} - y^{(i)} \right)^2 \end{equation}\]where \(\hat y^{(i)}\) is the result of the output neuron for example \(i\).
a) Suppose we use the sigmoid function as the activation function for \(a_1\), \(a_2\), \(a_3\) and \(\hat y\). What is the gradient descent update to \(w_{12}^{(1)}\), assuming we use a learning rate of \(\eta\)? Your answer should be written in terms of \(x^{(i)}\), \(\hat y^{(i)}\), \(y^{(i)}\). and the weights. (Hint: remember that \(\sigma'(x) = \sigma(x) (1 - \sigma(x))\)).
b) Now, suppose instead of using the sigmoid function for the activation function \(a_1\), \(a_2\), \(a_3\), and \(\hat y\), we instead use the step function \(f(x)\), defined as
\[f(x) = \begin{cases} 1, & x\geq 0\\ 0, & x < 0 \end{cases}\]What is one set of weights that would allow the neural network to classify this dataset with 100\% accuracy? Please specify a value for the weights in the following order and explain your reasoning:
\[w_{01}^{(1)}, w_{11}^{(1)}, w_{21}^{(1)}, w_{02}^{(1)}, w_{12}^{(1)}, w_{22}^{(1)}, w_{03}^{(1)}, w_{13}^{(1)}, w_{23}^{(1)}, w_0^{(2)}, w_1^{(2)}, w_2^{(2)}, w_3^{(2)}\]Hint: There are three sides to a triangle, and there are three neurons in the hidden layer.
c) Let the activation functions for \(a_1\), \(a_2\), \(a_3\) be the linear function \(f(x) = x\) and the activation for \(\hat y\) be the same step function as before. Is there a specific set of weights that will make the loss \(0\)? If yes, please explicitly state a value for every weight. If not, please explain your reasoning.
Problem 2: Kaggle Competition
Join Kaggle (create an account if you don’t have one) and participate in the following competition: LINK. You can participate in the competition as a team of up to 2 people or individually. Include the name of your team in the homework submission, and the team members.
You’re given a time series with the time stamps and the values of a variable. Your job is to predict the values of the variable at the time stamps given in the test set. Feel free to use any machine learning method you want. Save all your results/attempts in a Jupyter notebook and submit it with your assignment. As for the competition, you can submit your predictions once per day. Thus, the earlier you start, the more times you can submit!